Blog 6: Processing the Point Cloud – Cleaning & Filtering
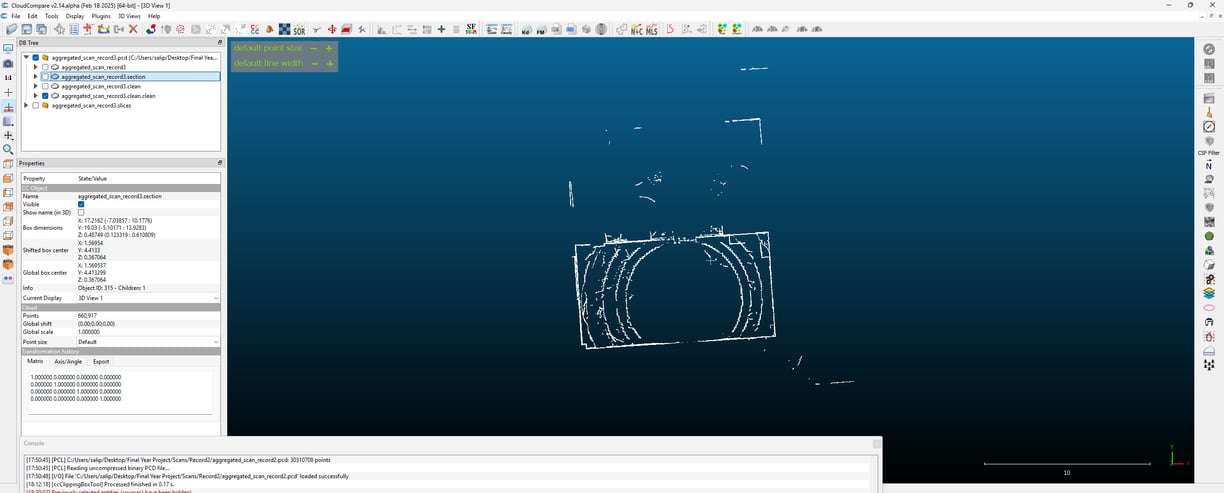
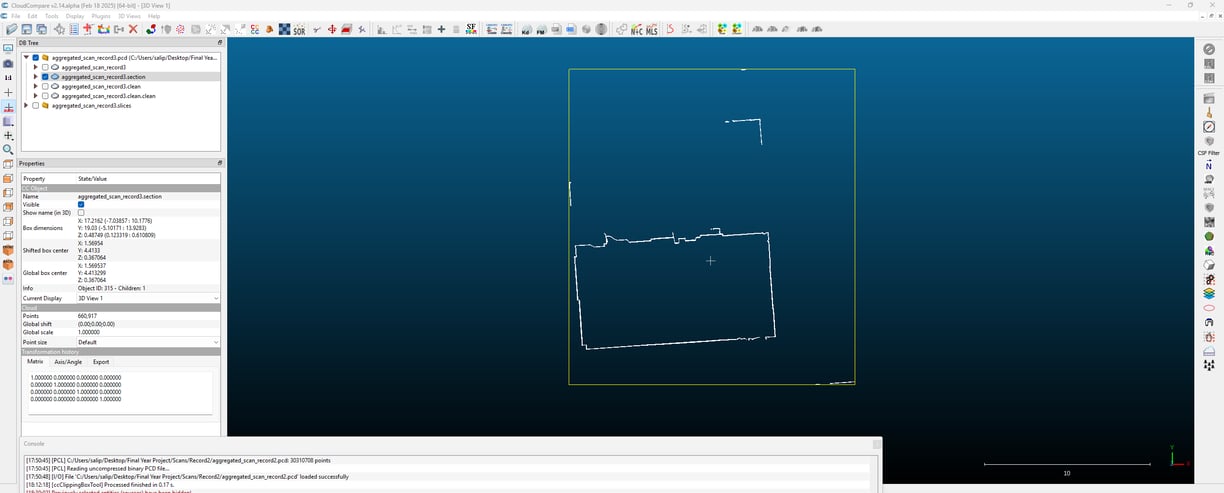
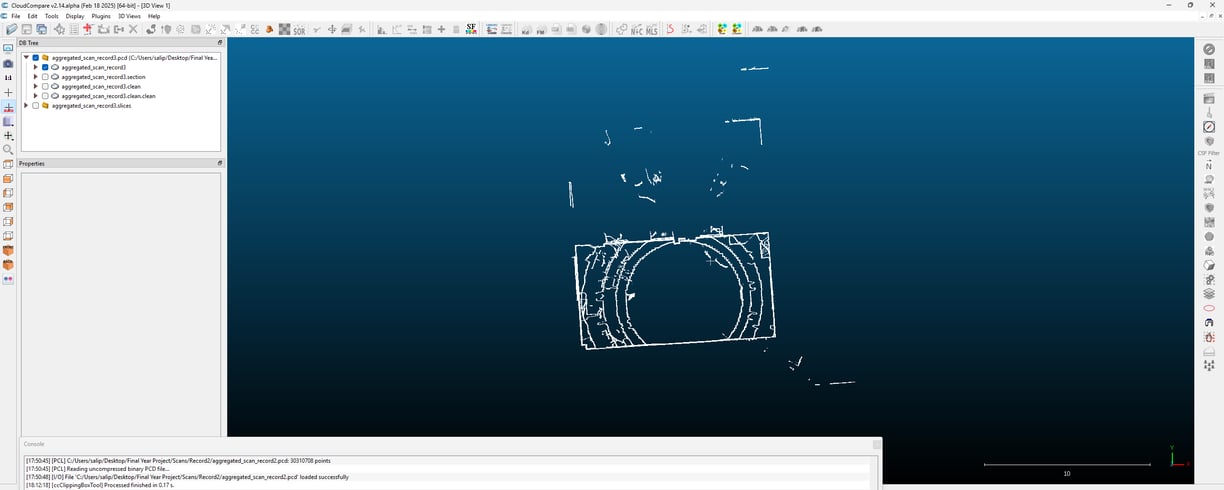
Now that I’ve merged multiple frames into a single scan, the next step is cleaning up the point cloud. Raw Lidar data isn’t perfect—it contains noise, scattered points, and unwanted details that need to be filtered out before proceeding. I’m testing different methods to refine the scan and remove unnecessary points to get a more structured dataset.
The first approach I tried was Statistical Outlier Removal (SOR). This method looks at each point and checks how far it deviates from its neighbours. If a point is too far from the others, it’s likely an error from the sensor and gets removed. It’s a simple but effective way to reduce random noise, especially in areas where the scan picks up stray reflections.
I also tested Radius Outlier Removal, which works slightly differently. Instead of checking statistical deviations, it looks at how many neighbouring points exist within a certain radius. If a point has too few neighbours, it’s probably not part of an actual surface and can be discarded. This was particularly useful for clearing isolated points that didn’t belong to any real structure.
I also ran a standard estimation since I’ll eventually need to extract meaningful features from the scan. This calculates the orientation of each point based on its surroundings, which will be useful later when I start segmenting different surfaces. It’s just a preprocessing step, but it helps lay the groundwork for identifying planes and structures in future steps.
After applying these filters, the point cloud looks much cleaner, with fewer stray points and a more uniform distribution. There’s still a lot of work ahead, but this step helps prepare the data for further analysis. The next challenge will be wall detection, which I’ll tackle in the next blog.